通常应用程序都运行在某个进程中,但kernel不同。kernel并不对应任何进程,它的工作是建立关于进程的抽象,创建并管理各个进程。kernel一个至关重要的功能是在实现进程之间切换。由kernel来调配各个应用程序的运行时间,可以防止程序过多(甚至是恶意)地占用系统资源。另外kernel在当前进程需要进行I/O等可能引起阻塞的操作时,可以选择将它挂起转而执行其他的进程,以避免在等待的过程中浪费过多的CPU时间。
xv6系列第7篇,其他还包括:
- minimal assembly
- how system boots
- address space
- interrupts
- system calls
- process
- context switch
- synchronization
- system initialization
基础设施
per-CPU state
xv6定义了cpu结构体:
// proc.h
struct cpu {
struct context *scheduler; // swtch() here to enter scheduler
struct taskstate ts; // Used by x86 to find stack for interrupt
struct segdesc gdt[NSEGS]; // x86 global descriptor table
volatile uint started; // Has the CPU started?
...
// Cpu-local storage variables; see below
struct cpu *cpu;
struct proc *proc; // The currently-running process.
};
// mp.c
struct cpu cpus[NCPU];
其中包括了调度线程的contextscheduler、管理task state地址的ts、公用的SDTgdt等。xv6创建了一个数组cpus统一管理各个CPU的状态。
在系统初始化时,seginit设置各个CPU的GDT:
void seginit(void) {
struct cpu *c;
c = &cpus[cpunum()];
c->gdt[SEG_KCODE] = SEG(STA_X|STA_R, 0, 0xffffffff, 0);
c->gdt[SEG_KDATA] = SEG(STA_W, 0, 0xffffffff, 0);
c->gdt[SEG_UCODE] = SEG(STA_X|STA_R, 0, 0xffffffff, DPL_USER);
c->gdt[SEG_UDATA] = SEG(STA_W, 0, 0xffffffff, DPL_USER);
// Map cpu and proc -- these are private per cpu.
c->gdt[SEG_KCPU] = SEG(STA_W, &c->cpu, 8, 0);
lgdt(c->gdt, sizeof(c->gdt));
loadgs(SEG_KCPU << 3);
// Initialize cpu-local storage.
cpu = c;
proc = 0;
}
除了通用的若干segemnt descriptor(SEG_KCODE、SEG_KDATA、SEG_UCODE、SEG_UDATA,各自定义了0~4 GB的线性地址空间)之外,GDT还包含了一个特殊的元素SEG_KCPU。SEG_KCPU描述的segment长度为8 bytes,起始地址指向cpus数组中与当前CPU对应的元素cpus[cpunum()]中的cpu字段。所以这个segment其实只包含两个元素:与当前CPU对应的cpu结构体的地址,和与当前CPU上运行的进程对应的proc结构体的地址。寄存器%gs中保存了指向SEG_KCPU的segment selector。
xv6可以通过以下方式访问当前CPU及其中运行的进程的状态:
extern struct cpu *cpu asm("%gs:0"); // &cpus[cpunum()]
extern struct proc *proc asm("%gs:4"); // cpus[cpunum()].proc
context
为实现切换前后寄存器状态的保存和恢复,xv6定义了结构体context:
struct context {
uint edi;
uint esi;
uint ebx;
uint ebp;
uint eip;
}
context包含了3个通用寄存器%edi、%esi和%ebx,base pointer即%ebp,以及program counter即%eip。这样的定义与调用规则相关。
进程间切换
kernel需要经常在各个进程之间切换,让各个进程都得到一定的在CPU上执行的时间窗口。进程的切换意味着它们的寄存器状态、栈以及program counter的切换。进程切换必须在kernel mode下进行。
context switch
swtch函数需要两个参数,第一个参数是一个指向指针的指针(struct context **old),被指的内存位置将用来保存旧进程kernel stack的最终位置;第二个参数是指向新进程的kernel stack最终位置的指针(struct context *new)。
进入swtch之后,首先将参数从旧进程的栈上备份到寄存器%eax(old)和%edx(new)中。根据调用规则,首先将%ebp压栈,然后将约定由被调函数备份的%ebx、%esi和%edi压栈。至此context结构体已经构建完毕。
最关键的步骤是从旧进程的栈切换到新进程的栈。swtch将%esp备份到old指针指向的内存位置,然后将new载入%esp中。最后从新进程的栈上恢复上一次切出时所保存的context,依次读出%edi、%esi、%ebx和%ebp(与压栈顺序相反)后,%eip在执行ret指令时恢复。
# void swtch(struct context **old, struct context *new);
.globl swtch
swtch:
movl 4(%esp), %eax # struct context **old
movl 8(%esp), %edx # struct context *new
# Save old callee-save registers
pushl %ebp
pushl %ebx
pushl %esi
pushl %edi
# Switch stacks
movl %esp, (%eax)
movl %edx, %esp
# Load new callee-save registers
popl %edi
popl %esi
popl %ebx
popl %ebp
ret
如果追踪各个寄存器的状态的话,根据调用规则,%eax、%ecx、%edx在进入swtch函数之前压栈,%eip在执行call指令时压栈,%ebp、%ebx、%esi、%edi在swtch函数中通过pushl指令压栈(注意顺序,它们和%eip共同构成了context结构体),最后%esp在两个进程的kernel stack之间切换。
timer interrupt
xv6使用强制性的调度机制,定时地在进程间切换,以保证各个进程都有被执行的机会。主板上的计时器定时发出中断信号IRQ_TIMER。在IDT中,所有有外部I/O设备发来的interrupt信号都被对应到序号IRQ0(数值32)之后的gate上。于是处理器经由序号为IRQ0+IRQ_TIMER的gate进入trap函数:
// trap.c
extern struct proc *proc asm("%gs:4"); // cpus[cpunum()].proc
void trap(struct trapframe *tf) {
...
if(proc && proc->state == RUNNING && tf->trapno == T_IRQ0+IRQ_TIMER)
yield();
}
// proc.c
void yield(void) {
acquire(&ptable.lock); //DOC: yieldlock
proc->state = RUNNABLE;
sched();
release(&ptable.lock);
}
trap函数检查trapno,然后进入yield函数令当前进程让出CPU。yield首先获得ptable锁。然后将当前进程的状态设为RUNNABLE,然后进入调度函数sched。注意从获得ptable锁之后,中断已经被禁止。
void sched(void) {
int intena;
if(!holding(&ptable.lock))
panic("sched ptable.lock");
if(cpu->ncli != 1)
panic("sched locks");
...
intena = cpu->intena;
swtch(&proc->context, cpu->scheduler);
cpu->intena = intena;
}
sched首先会检查当前进程是否锁定了ptable,以及是否释放了其他所有的锁(为避免切换进程之后出现死锁的情况)。然后通过swtch从当前进程切换到CPU的调度线程cpu->scheduler中。
scheduler
CPU的调度线程是初始化时为实现进程切换而准备的一个特殊“线程”,scheduler处于一个循环之中:它首先锁定ptable,然后遍历进程表,找到一个RUNNABLE的进程p,将它载入cpu结构体的proc字段之中,通过switchuvm将进程p的task state保存到cpu的ts字段之中,然后通过swtch切换到进程p中。
void scheduler(void) {
struct proc *p;
for(;;){
// Enable interrupts on this processor.
sti();
// Loop over process table looking for process to run.
acquire(&ptable.lock);
for(p = ptable.proc; p < &ptable.proc[NPROC]; p++){
if(p->state != RUNNABLE)
continue;
proc = p;
switchuvm(p);
p->state = RUNNING;
swtch(&cpu->scheduler, p->context);
switchkvm();
// Process is done running for now.
// It should have changed its p->state before coming back.
proc = 0;
}
release(&ptable.lock);
}
}
此时进程p有两种情况,一种是处于上一次从CPU中切出的状态中,它的执行流程处于sched函数中swtch结束之后的位置。它将逆着之前收到timer interrupt之后的处理流程运行,从sched返回到yield中,释放ptable锁,然后返回trap函数中,然后进入trapret过程从中断中返回。另一种情况p是新创建的进程(通过fork或者userinit),它将进入forkret,释放ptable锁,最后同样进入trapret过程。
一段时间之后,当进程p再次收到timer interrupt信号,它将再次通过swtch切换到CPU的scheduler中。此时scheduler位于swtch结束的位置,接下来它将释放ptable锁然后进入下一个循环,寻找新的RUNNABLE进程。
在进程切换的过程中还有若干值得注意的细节:
scheduler在每次进入循环就对ptable加锁,直至离开才解锁,所以在scheduler中绝大部分时间ptable都处于锁定状态。每次加锁解锁是为了避免在进程表中找不到RUNNABLE进程时,各个CPU的调度线程陷入死锁的状态。- 通常对一个锁来说,进程在加锁的同时也应该负责解锁的操作。但在进程切换过程中的
ptable锁是由切出进程加锁,由切入进程解锁。其中一个例子就是forkret。forkret是一个新建进程自创建完毕之后开始运行的第一步,而它的第一个操作就是对ptable解锁。这看似奇怪的操作是因为进入forkret函数的路径是由scheduler进行context switch,而scheduler在swtch之前对ptable加了锁。
void forkret(void) {
...
// Still holding ptable.lock from scheduler.
release(&ptable.lock);
...
}
总结来说,在两个用户进程之间切换时需要CPU的调度线程作为中介,进程切换的过程如下图所示:
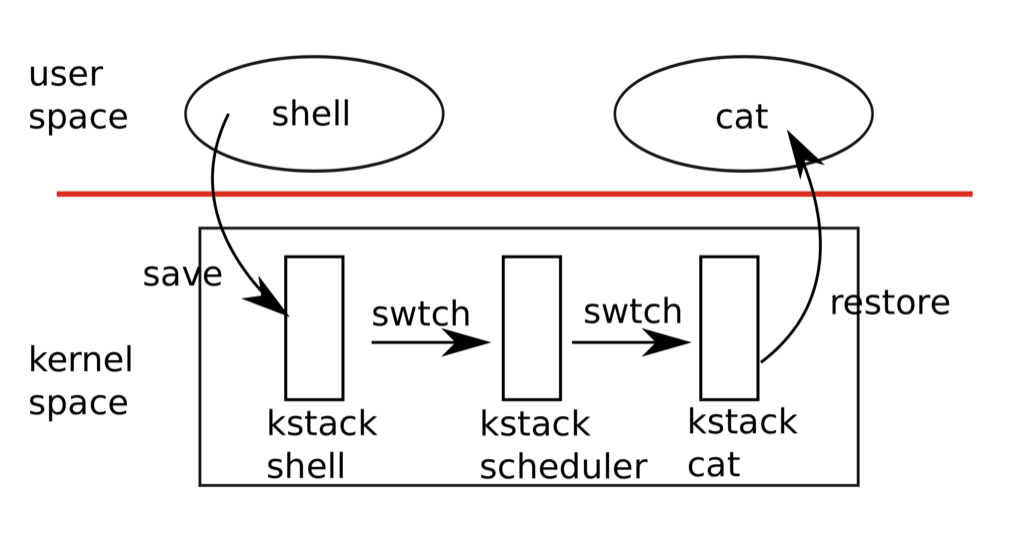
xv6的调度规则是顺序遍历进程表,找到一个可执行进程就进行切换。这难以保证公平,也很难实现优先级控制等功能。现实中的调度器通常会支持更为复杂的调度策略。