所谓“地址空间”是对于物理内存的一种抽象,它所描述的是一个应用程序所看到的系统内存分配状况。xv6的内存管理主要依靠分页的办法,通过分页表来为应用程序配置地址空间。每个进程各自维护一张独立的分页表,从而实现进程之间的内存隔离。进程内部则通过将地址空间切分user和kernel两个部分来实现权限的分级管理。
本篇是xv6系列的第3篇。xv6系列包括:
- minimal assembly
- how system boots
- address space
- interrupts
- system calls
- process
- context switch
- synchronization
- system initialization
机制
多级分页
使用分页机制管理内存时,系统需要借助分页表来维护从线性地址到物理地址的映射关系。分页表可能会很长,例如x86中内存地址长度为232位。如果设定一页的长度为212位(4 kB),那就总共需要220(1,048,576)个page table entry(PTE)。假设一个PTE占用4 bytes,那么一张完整的分页表将占用4 MB内存。4 MB也许不能算是很大的开销,但为了实现内存隔离,各个进程维护各自独立的分页表,于是系统也许需要同时保存成百上千张分页表。如果没有适当的优化,分页表本身将占用若干GB的空间。
为解决内存开销过大的问题,一种方法是使用更粗的分页(相应更短的分页表),但这可能导致分页内部的内存浪费,以及虚拟内存换入/换出时的困难。另一种方法是引入多级分页,xv6使用的就是二级分页的方法。
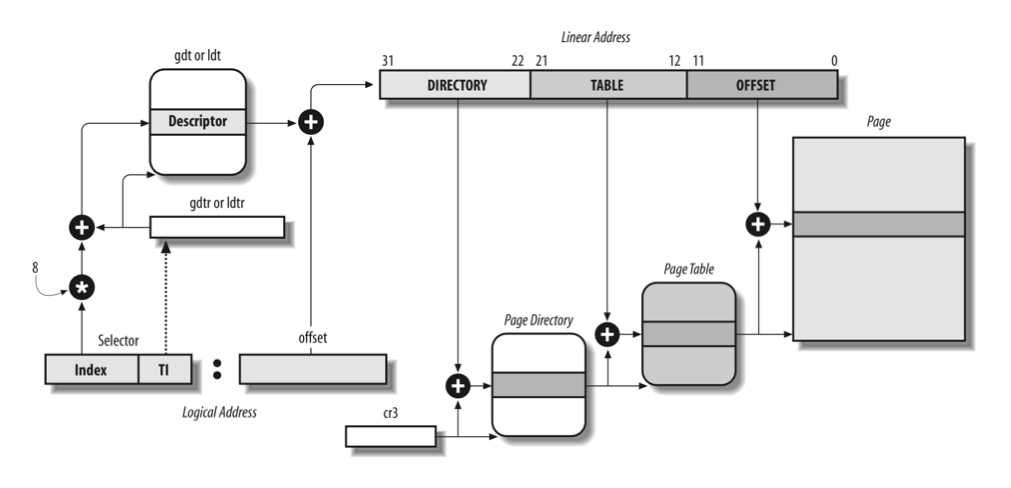
具体来说,xv6将线性地址分为三段,其中前10个比特位称为为page directory index(PDX),第11至20个比特位称为page table Index(PTX),最后12位为offset:
// mmu.h
// A virtual address 'va' has a three-part structure as follows:
//
// +--------10------+-------10-------+---------12----------+
// | Page Directory | Page Table | Offset within Page |
// | Index | Index | |
// +----------------+----------------+---------------------+
// \--- PDX(va) --/ \--- PTX(va) --/
// page directory index
#define PDX(va) (((uint)(va) >> PDXSHIFT) & 0x3FF)
// page table index
#define PTX(va) (((uint)(va) >> PTXSHIFT) & 0x3FF)
相对应的,系统首先维护一个初级分页表(page diretory table,PDT),包含210个PTE,占用一个4 kB的内存页,其中每一个PTE指向一个二级分页表。每个二级分页表也各自包含210个PTE,占用一个4 kB内存页。地址的转译过程是,首先获取线性地址中的PDX部分,在PDT中查找相应的PTE,如果命中,则读取对应的二级分页表。然后在二级分页表中根据线性地址的PTX部分查找对应的PPN,如果命中,则用PPN加上offset,就获得最终的物理地址。
这样一个完整的分页表最多可以管理4 GB的地址空间。二级分页节省内存的关键是,当一个二级分页表所对应的线性地址完全没有被占用时,这个分页表本身也不需要存在,只需要将PDT中对应行的PTE_P标志位置0即可。通常情况下分页表相对稀疏,因而大量二级分页表都不需要额外占用空间,由此大大降低了内存开销。
作为一个总结,xv6系统中地址转译的完整过程(包括segment和paging)如下图所示:
权限控制
x86的segment机制中就包含权限控制,segment selector和segment descriptor中都包含用以标示权限的标志位privilege level(PL)。PL通常占用2个比特位,原则上可以标识4种不同的权限等级。xv6只使用了其中的两个等级:0(kernel mode)和3(user mode)。一些关键的操作(例如异常处理、硬件I/O、system call)只能在kernel mode中进行。
但事实上xv6在内存管理上几乎不依赖segment机制,SDT中设定的各个全局segment descriptor(code、stack、data等)都覆盖了[0, 4 GB)的线性地址空间。权限保护是通过分页表PTE中的特殊标志位PTE_U来实现。只用当PTE_U设置为1时,对应的地址空间才允许在user mode下访问。
分配模型
xv6中每个进程都独立拥有4 GB的独立地址空间,其中包括user[0 ~ 2 GB)和kernel[2 ~ 4 GB)两部分,地址空间分配如下图所示。
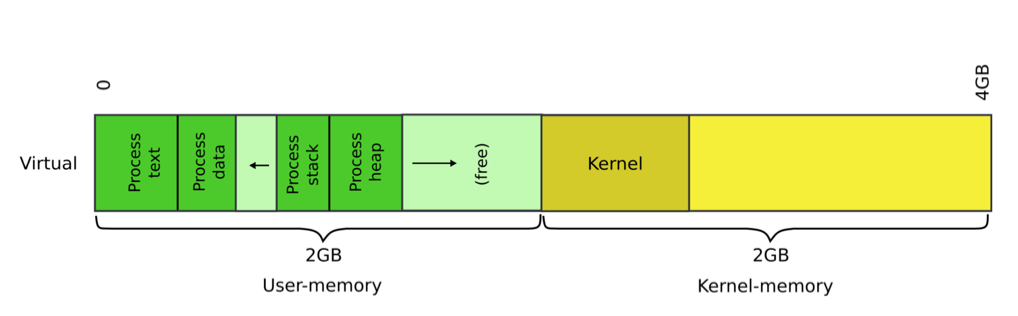
用户进程通常运行在user mode下,使用user部分的地址空间。当程序需要进行I/O、异常处理等操作时,进程通过中断机制提升权限进入kernel mode,转而执行kernel中预设的指令(interrupt handlers)。与两种权限等级相对应,每个进程都拥有两个栈:user stack和kernel stack。
实现
分页管理
结构体kmem负责管理分页。kmem维护了一个包含所有可用分页的链表freelist:
// kalloc.c
struct run {
struct run *next;
};
struct {
struct spinlock lock;
int use_lock;
struct run *freelist;
} kmem;
- allocate a page
当程序需要更多内存的时候,kernel通过kalloc取出freelist中的第一个分页以供使用,同时令freelist指向下一个可用分页。
char* kalloc(void) {
struct run *r;
if(kmem.use_lock)
acquire(&kmem.lock);
r = kmem.freelist;
if(r)
kmem.freelist = r->next;
if(kmem.use_lock)
release(&kmem.lock);
return (char*)r;
}
- free a page
kfree首先填充需要释放的分页(避免下一个使用此页的进程可以读到上一个进程写入的内容),然后将它插入到freelist头部的位置。
void kfree(char *v) {
struct run *r;
// Check if v is legitimate,
if((uint)v % PGSIZE || // v必须为合法的页起始位置,即PGSIZE的整数倍
v < end || // v不得低于end:end是kernel本身占用内存的最高位置,定义在kernel.ld中
V2P(v) >= PHYSTOP) // v对应的物理地址不得高于PHYSTOP
panic("kfree");
// Fill with junk to catch dangling refs.
memset(v, 1, PGSIZE); // PGSIZE = 4 kB
if(kmem.use_lock)
acquire(&kmem.lock);
r = (struct run*)v;
r->next = kmem.freelist;
kmem.freelist = r;
if(kmem.use_lock)
release(&kmem.lock);
}
- free a range
freerange将vstart至vend之间的虚拟地址段分成若干大小为PGSIZE的页,插入freelist中。
void freerange(void *vstart, void *vend) {
char *p;
p = (char*)PGROUNDUP((uint)vstart);
for(; p + PGSIZE <= (char*)vend; p += PGSIZE) // PGSIZE = 4 kB
kfree(p);
}
freerange在初始化的过程中非常有用。xv6在main函数中就通过freerange将kernel的end到P2V(PHYSTOP)之间的VA区间切分成大小为4 kB的小段,依次插入到freelist中。PHYSTOP的值为0xe000000,xv6实际可以操作的地址空间小于224 MB。
kmem直接操作的VA,实际上管理的是PA。
设置分页表
mappages的作用是在分页表pgdir中设置虚拟地址到物理地址的对应关系。它将从va开始的一段长度为size的连续虚拟地址空间映射到与之对应的从pa开始的一段物理地址空间。
mappages通过walkpgdir来查找虚拟地址va对应的PTE。walkpgdir的流程是:
- 首先根据
PDX(va)查找va在初级分页表pgdir中对应的PDE,读取对应二级分页表的物理地址 - 如果对应的二级分页表不存在并且参数
alloc设为1时,就通过kalloc申请一个新的内存页 - 然后根据
PTX(va)查找va在二级分页表中对应的PTE并返回
walkpgdir最后返回与va对应PTE,然后mappages将pa写入到PTE的PPN中,并设置PTE_P标记位,标示这段地址已经被占用。
// vm.c
static pte_t *walkpgdir(pde_t *pgdir, const void *va, int alloc) {
pde_t *pde;
pte_t *pgtab;
pde = &pgdir[PDX(va)];
if(*pde & PTE_P){ // 判断二级分页表pgtab是否存在
pgtab = (pte_t*)P2V(PTE_ADDR(*pde));
} else {
if(!alloc || (pgtab = (pte_t*)kalloc()) == 0)
return 0;
memset(pgtab, 0, PGSIZE); // 置0,保证pgtab中所有的PTE_P标志位为0
*pde = V2P(pgtab) | PTE_P | PTE_W | PTE_U;
}
return &pgtab[PTX(va)];
}
static int mappages(pde_t *pgdir, void *va, uint size, uint pa, int perm) {
char *a, *last;
pte_t *pte;
a = (char*)PGROUNDDOWN((uint)va);
last = (char*)PGROUNDDOWN(((uint)va) + size - 1);
for(;;){
if((pte = walkpgdir(pgdir, a, 1)) == 0)
return -1;
if(*pte & PTE_P)
panic("remap");
*pte = pa | perm | PTE_P;
if(a == last)
break;
a += PGSIZE;
pa += PGSIZE;
}
return 0;
}
kernel地址空间
xv6对kernel地址空间的分配定义在kmap中:
static struct kmap {
void *virt;
uint phys_start;
uint phys_end;
int perm;
} kmap[] = {
{ (void*)KERNBASE, 0, EXTMEM, PTE_W}, // I/O space, KERNBASE = 0x80000000(2 GB)
{ (void*)KERNLINK, V2P(KERNLINK), V2P(data), 0}, // kern text+rodata, KERNLINK = 0x80100000(2 GB + 1 MB)
{ (void*)data, V2P(data), PHYSTOP, PTE_W}, // kern data+memory, PHYSTOP = 0xe000000(224 MB)
{ (void*)DEVSPACE, DEVSPACE, 0, PTE_W}, // more devices, DEVSPACE = 0xfe000000
};
其中包括4段物理内存:
- 0 ~
EXTMEM(0x100000, 1 MB):EXTMEM是kernel在物理内存中的起始位置,EXTMEM之前的地址被boot等占用。 EXTMEM~P2V(data):data在链接脚本(kernel.ld)中定义,是kernel只读部分终止的位置。kernel只读部分包括了text(指令)和rodata(常量数据)等P2V(data)~PHYSTOP: 可读可写区域,包括了kernel可写的数据以及未分配的空间。kernel的结束位置end就处于此区间中。- 最后是一段硬件预留的空间
kmap将它们映射到kernel部分的虚拟地址空间中(加上2 GB的KERNBASE)。
setupkvm函数创建kernel地址空间:
- 首先通过
kalloc申请一页内存(4 kB)内存作为PDT - 将这段内存的内容置零,以保证所有PTE的
PTE_P标志位为零 - 遍历
kmap,通过mappages将kmap中定义的各段虚拟地址到物理地址的映射关系以及权限写入到相应PTE中
pde_t* setupkvm(void) {
pde_t *pgdir;
struct kmap *k;
if((pgdir = (pde_t*)kalloc()) == 0) // 申请4 kB空间作为PDT
return 0;
memset(pgdir, 0, PGSIZE); // 置0,初始化PDT
for(k = kmap; k < &kmap[NELEM(kmap)]; k++)
if(mappages(pgdir, k->virt, k->phys_end - k->phys_start,
(uint)k->phys_start, k->perm) < 0)
return 0;
return pgdir;
}
setupkvm返回一个PDT的地址pgdir。其中user部分(2 GB以下)为空白,kernel部分(2 GB以上)的地址空间已经设置完毕。此处一个细节是,setupkvm将kmap所描述的完整的物理内存空间(从0到PHYSTOP,以及DEVSPACE)都加载进了pdgir的kernel部分,因而此后当kernel通过kalloc获得新的内存页时,不需要更新分页表。与之对应,当user程序申请更多分页时(经由名为sbrk的system call实现),每次都需要调用mappages来将新的分页设置到pgdir的user部分中(具体见下一节allocuvm函数)。
user地址空间
allocuvm为user部分分配内存。当需要更多内存(newsz>oldsz)时,allocuvm通过kalloc申请新的分页mem,重置分页的内容,而后通过mappages将user地址a到mem之间的映射关系写入到pgdir中。
int allocuvm(pde_t *pgdir, uint oldsz, uint newsz) {
char *mem;
uint a;
...
a = PGROUNDUP(oldsz);
for(; a < newsz; a += PGSIZE){
mem = kalloc(); // 申请新的分页
if(mem == 0){
cprintf("allocuvm out of memory\n");
deallocuvm(pgdir, newsz, oldsz);
return 0;
}
memset(mem, 0, PGSIZE); // 重置分页内容
if(mappages(pgdir, (char*)a, PGSIZE, V2P(mem), PTE_W|PTE_U) < 0){ // 设置PTE
cprintf("allocuvm out of memory (2)\n");
deallocuvm(pgdir, newsz, oldsz);
kfree(mem);
return 0;
}
}
return newsz;
}
在申请足够的地址空间之后,loaduvm在pgdir中找到相应的PTE,读取其中的PPN,并通过readi将硬盘上的可执行文件(elf)载入这个地址。
int loaduvm(pde_t *pgdir, char *addr, struct inode *ip, uint offset, uint sz) {
uint i, pa, n;
pte_t *pte;
...
for(i = 0; i < sz; i += PGSIZE){
if((pte = walkpgdir(pgdir, addr+i, 0)) == 0)
panic("loaduvm: address should exist");
pa = PTE_ADDR(*pte);
if(sz - i < PGSIZE)
n = sz - i;
else
n = PGSIZE;
if(readi(ip, P2V(pa), offset+i, n) != n)
return -1;
}
return 0;
}
一个栗子:复制分页表
copyuvm在创建进程时用到。unix中新进程从父进程fork而来。在fork完成的时候,子进程和父进程使用相同的地址空间,copyuvm的工作就是将父进程的分页表复制到子进程中:
- 首先
setupkvm获得一个新的分页表d。setupkvm的流程是通过kalloc申请内存页作为PDT,并设置其中与kernel相关的部分 - 通过
walkpgdir遍历父进程的分页表pgdir中属于的user部分的各个PDE,获得父进程中各个二级分页表的物理地址pa - 通过
kalloc为子进程的各个二级分页表申请空间mem。通过memmove将P2V(pa)的内容复制到mem中 - 最后通过
mappages将新的二级分页表的物理地址V2P(mem)写入到d中对应的PDE里。
pde_t* copyuvm(pde_t *pgdir, uint sz) {
pde_t *d;
pte_t *pte;
uint pa, i, flags;
char *mem;
if((d = setupkvm()) == 0)
return 0;
for(i = 0; i < sz; i += PGSIZE){
if((pte = walkpgdir(pgdir, (void *) i, 0)) == 0)
panic("copyuvm: pte should exist");
if(!(*pte & PTE_P))
panic("copyuvm: page not present");
pa = PTE_ADDR(*pte);
flags = PTE_FLAGS(*pte);
if((mem = kalloc()) == 0)
goto bad;
memmove(mem, (char*)P2V(pa), PGSIZE);
if(mappages(d, (void*)i, PGSIZE, V2P(mem), flags) < 0)
goto bad;
}
return d;
bad:
freevm(d);
return 0;
}
最后值得注意的是,xv6将kernel的指令和数据加载到了每一个进程的地址空间中。这样设计的用意是当应用程序需要使用某些kernel的功能时,就不需要额外执行一次切换分页表的操作,从而节省了CPU时间。尽管如此,应用程序并不能直接调用kernel中的函数。这是因为应用程序通常运行在user mode下,而kernel中的函数必须在权限等级更高的kernel mode中才能执行。此时应用程序需要借助“中断”机制来提升权限。